Materials (241 MB)
Download all materialsData Наборы данных, целевая переменная и информационный файл. | 240 MB | |
Baseline Базовый пример решения от организаторов в виде Jupyter-notebook’а | 1 MB |
Данные
Для решения задачи участникам предоставляется информация о транзакциях клиентов банка. Объемом около 27 000 000 миллионов записей.
Каждая запись описывает одну банковскую транзакцию. Для каждого из ≈20 000 тестовых id, участникам необходимо с помощью обученной модели предсказать — в какую из возрастных групп попадает Клиент.
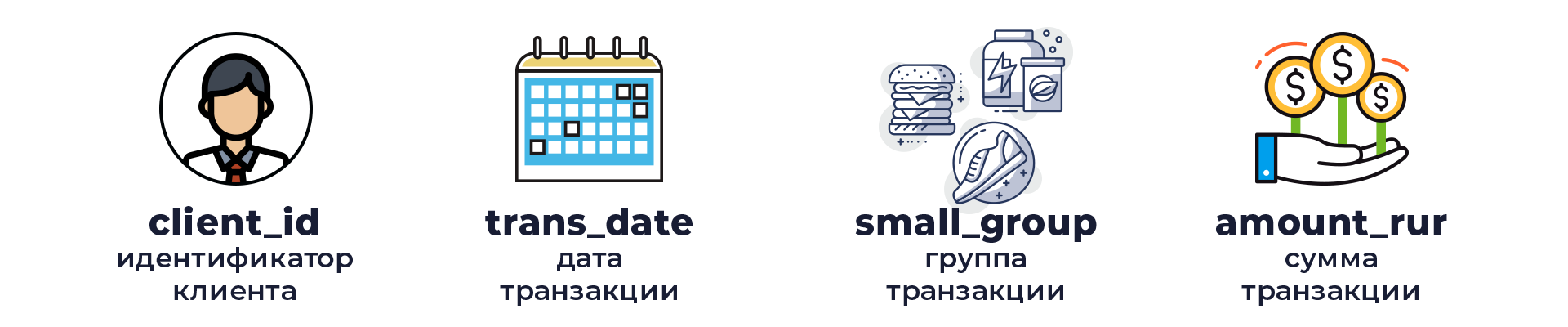
Мы подготовили два набора данных:
- Обучающий
transactions_train.csv, в котором для каждой транзакции известна дата, сумма, тип и id клиента; - Тестовый
transactions_test.csv, содержащий те же поля:- сlient_id – уникальный номер клиента;
- trans_date – дата транзакции (представляет из себя просто номер дня в хронологическом порядке, начиная от заданной даты);
- small_group – группа транзакций, характеризующих тип транзакции (например, продуктовые магазины, одежда, заправки, детские товары и т.п.);
- amount_rur – сумма транзакции (для анонимизации данные суммы были трансформированы без потери структуры).
Целевая переменная для обучающего датасета находится в файле train_target.csv. В нем содержится информация о Клиенте и метка возрастной группы, к которой он относится:
- client_id – уникальный номер Клиента (соответствует client_id из файла
transactions_train.csv); - bins – метка возраста. В файлe
test.csvвам надо предсказать для указанных client_id соответствующую метку группы возраста.
Участникам также предоставлен информационный файл small_group_description.csv, который содержит расшифровку типов транзакций.
Формат решений
Для каждого примера из тестового набора необходимо предсказать возрастную группу к которой относится клиент. В систему необходимо предоставить для проверки CSV-файл с предсказаниями, он должен содержать две колонки:
- client_id — идентификатор клиента;
- bins — возрастная группа.

Пример выходных данных:
client_id,bins 0,0 7,1 9,0 10,2 11,1 15,3 ...
Задача представляет из себя мультиклассовую классификацию (4 класса – от 0 до 3). Качество решения считается как доля верно угаданных меток возраста по всем тестовым примерам - accuracy.
Для решения удобнее всего использовать язык программирования Python, так как для него есть большое число библиотек для анализа данных: NumPy, Pandas, SciKit-Learn и другие. В качестве инструмента разработки — интерактивную среду Jupyter.
Участникам также доступен базовый пример решения от организаторов в виде Jupyter-notebook’а.
Our website uses cookies, including web analytics services. By using the website, you consent to the processing of personal data using cookies. You can find out more about the processing of personal data in the Privacy policy