Хакатон Академии ИИ «По следам животных»: призовой фонд – 1 000 000 рублей.
Прими участие в заключительном хакатоне этого года от Академии ИИ! Ты сможешь попасть в сообщество самых сильных специалистов по ИИ среди школьников, а еще выиграть реальные деньги уже в школе!


Правила участия
Нажимая кнопку «Отправить решение», вы соглашаетесь с Правилами участия в соревновании.
Марафон подготовки
Вместе с хакатоном стартует образовательный марафон, который поможет подготовиться к хакатону и увеличит шансы на победу. Переходи по ссылке на канал!
- Вы узнаете, как работать с переменными, функциями, циклами, списками и словарями, чтобы уверенно писать код.
- Поймете базовые математические принципы работы нейронок и научитесь использовать искусственный интеллект для написания кода.
- Познакомитесь с задачей, проанализируете базовое решение и запустите его, чтобы понять, как оно работает!
Образовательный марафон подойдет даже новичкам и поможет лучше подготовиться к хакатону.
Описание задачи
Мониторинг популяции диких животных — важная задача для мирового сообщества исследователей дикой природы. Её решение помогает узнать, какие виды животных находятся под угрозой исчезновения, как они себя ведут в разные периоды жизни, где обитают и многое другое.
Для мониторинга животных используют различные инструменты, в том числе и фотоловушки — специальные камеры, устанавливаемые в лесу и реагирующие на движение в кадре.
Каждый год с этих камер приходят сотни тысяч фотографий, на которых нужно найти и классифицировать животных. Это сложная и кропотливая работа, так как число видов может достигать нескольких сотен, включая сложно различимые виды.
Качество снимков с фотоловушек значительно отличается от профессиональных фото. Исследователям необходимо обрабатывать фото, полученные в разное время суток и время года, содержащие часть животного или группу животных, перекрывающих друг друга.
В рамках хакатона мы предлагаем вам помочь учёным автоматизировать рутинную работу по обработке данных с фотоловушек, обучив для этого модели машинного обучения.
Для первичной фильтрации сырых данных и дальнейшей обработки (аналитики и изучения каждой отдельной особи) вам потребуется разработать модель которая позволит сегментировать каждую отдельную особь класса “animal" на фотографиях.
Использование сегментации в процессе обработки фотографий с фотоловушек помогает:
- Точнее определять контуры животных, что позволяет избежать ошибок при подсчете из-за наложения объектов.
- Уменьшить влияние различных условий съемки и фона (например, листвы, земли или камней).
Метрика
Для оценки качества работы модели сегментации используется метрика mAP 0.5-0.95 - подсчет средней точности (AP - Average Precision) при различных значениях порога IoU (Intersection over Union) от 0.5 до 0.95 с шагом 0.05 (минимальное IoU для рассмотрения положительного совпадения).
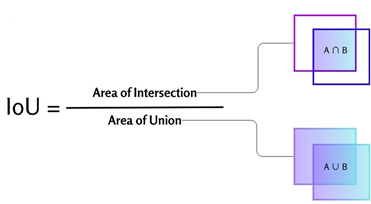
Вычисляется среднее значение AP по всем порогам IoU:
$$\text{mAP}_{c} = \frac{1}{N} \sum_{i=1}^{N} \text{AP}_{c, \tau_i} $$
где N = 10 — количество значений порога IoU (от 0.5 до 0.95 с шагом 0.05).
Значение метрики варьируется от 0 (в худшем случае) до 1, если все маски точно совпадают с истинными.
Подсчет метрики производится автоматически на платформе при отправке решения.
Данные
Датасет представляет собой набор изображений и файлы train_annotations.json, val_annotations.json с соответствием каждого изображения и маски для каждого животного на изображении.
Обратите внимание, что в датасете присутствуют сложные примеры: фото, когда в кадр попала небольшая часть животного, много животных перекрывающих друг друга, а также ночные и смазанные снимки. Данные были размечены специалистами по разметке данных совместно с учеными зоологами.
Обучающая выборка разбита на тренировочную и валидационную 70% / 30%.
Данные разделены на тренировочную и тестовую выборки в соотношении примерно 70% / 30%.
Тестовая часть разбита на публичную и приватную в соотношении примерно 40% / 60%.
Файлы train_annotations.json, val_annotations.json представлены в COCO формате.
Корневая структура json файлов:
categoriesсодержит список категорий, к которым могут принадлежать аннотации (все аннотации принадлежат к категории animal)imagesсодержит информацию о изображениях, которые аннотируются(id, width, height, file_name)annotationscодержит аннотации для изображений, включая информацию о сегментации и ограничивающие прямоугольники.
Пример файла train_annotations.json для изображения IMG_1.JPG:
{
"categories": [
{
"id": 0,
"name": "Animal",
"supercategory": ""
}
],
"images": [
{
"id": 0,
"width": 3648,
"height": 2736,
"file_name": "IMG_1.JPG",
"license": 0,
"flickr_url": "",
"coco_url": "",
"date_captured": 0
},
{}
],
"annotations": [
{
"id": 1,
"image_id": 0,
"category_id": 1,
"segmentation": [
[
1004.0,
2133.0,
1038.0,
2045.0,
1086.0,
1978.0,
1130.0,
1910.0,
1179.0,
1850.0,
…
1094.0,
2145.0
]
],
"area": 391337.0,
"bbox": [
1004.0,
1719.0,
1382.0,
537.0
],
"iscrowd": 0,
"attributes": {
"occluded": false
}
},
{}
]
}
Baseline (базовое решение)
Приведенный пример решения задачи инстанс сегментации животных на изображении базируется на библиотеке detectron2(архитектура Mask R-CNN) с использованием аннотаций в формате COCO.
Во время обучения Mask R-CNN оптимизирует несколько задач одновременно:
- Обнаружение объектов (с помощью RPN и классификации).
- Сегментация масок (с помощью дополнительной ветви).
- Уточнение координат рамок объектов.
Бейзлайн позволяет пройти путь от установки библиотек и обучения модели до получения файла с предсказаниями и посмотреть визуально результаты работы алгоритма.
Формат решения
Соревнование подразумевает отправку файла с предсказаниями модели на платформу для расчета метрики. Сам файл должен представлять собой json документ в COCO формате.
Корневая структура содержит следующие ключи:
• image_name
• category_id
• bbox
• score
• segmentation
Пример файла с предсказаниями:
{
"image_name": “img_1.JPG”,
"category_id": 0,
"bbox": [
1003.3180541992188,
1726.681884765625,
1215.438720703125,
495.12744140625
],
"score": 0.938715934753418,
"segmentation": {
"size": [
2736,
3648
],
"counts": "b'QSd:5f0LPd0=c[OLTd0P1UJhNgE7\\\\Lc1j=\\\\NSBNf2;VM_1n=\\\\NPB3f24YMa1b0nM_<N1O1O101N1O1O100O2N1O1O1O1O2N1O1O100O2N1O1O100O2N1O1O1O100O2N1O1O1O1O2N1O1O100O101N1O100O100O1O100O1O100O1O100O1O1O100O1O1O1O1O1O1O1O1O100O1O1O1O1O1O1O1O1O1O1O1O1O1O100..."
}
}
где:
category_id- идентификатор категории, к которой принадлежит объект на изображении. В данном примере значение равно1.image_name- название файла, содержащего изображение, к которому относится аннотация. В данном примере значение равно “img_1.JPG”.bbox- ограничивающий прямоугольник (bounding box) для объекта на изображении,- Формат:
[x, y, width, height],x,y: Координаты верхнего левого угла,width: Ширина ограничивающего прямоугольника,height: Высота ограничивающего прямоугольника.
- Формат:
score- уверенность модели в том, что объект на изображении соответствует указанной категории. Значение варьируется от0до1, где1означает максимальную уверенность. В данном примере значение равно0.938715934753418.segmentationсодержит информацию о сегментации объекта на изображении,-
sizeМассив чисел (Array of Integers) Размеры изображения в формате[height, width]. В данном примере значение равно[2736, 3648], countsЗакодированные данные сегментации в формате RLE (Run-Length Encoding). Это строка, которая представляет собой сжатое представление маски сегментации, где каждый элемент указывает на количество последовательных пикселей одного цвета и их значение.
-
Использование сторонних датасетов
Допускается использование открытых (доступных в сети) датасетов с лицензией, позволяющей свободное некоммерческое использование.
Для того чтобы мы могли воспроизвести ваше решение, необходимо предоставить все использованные открытые датасеты в том формате, в котором они были применены для обучения.
Внимание.
Приватный обмен идеями (private sharing), решениями и кодом между участниками — запрещен. В случае обнаружения этого факта, все причастные решения аннулируются.
Ручная разметка данных запрещена.
Все участники, занявшие призовые места должны прислать воспроизводимые решения.
Our website uses cookies, including web analytics services. By using the website, you consent to the processing of personal data using cookies. You can find out more about the processing of personal data in the Privacy policy