Мы подготовили новое практические задание №2 с учетом новых архитектур
nlphuaweitaskclassificationmulticlass
Practical Assignment 2: Text multiclass classification: movie's genre
The design of an upgraded version of the second practice assignment for the «Natural Language Processing course» by HUAWEI company is presented in the current survey. The contribution to this course includes an expanded dataset, four baseline pipelines and a flexible point distribution for student assessment. It is believed that a new assignment will be a valuable opportunity for students to practise their skills in pipeline creation, model fine-tuning and comparison analysis.
This project appeared during the Natural Language Processing course (stream 3, autumn 2022).
Motivation
The first practical assignment of the NLP course is related to classical methods and its implementation from scratch, while the second practical task aims at maximizing metrics using arbitrary tools. Almost all real-world projects require developers to fine-tune previously implemented and trained models for specific cases. The skills of choosing parameters, analysing appropriate solutions and fine-tuning them for use cases are essential for implementing comprehensive architectures. Therefore, the idea of the discussed task is indeed created to practise these skills. We implement four baselines based on both state-of-the-art solutions and base algorithms for further detailed implementation by the students.
Dataset
The RT-movie dataset was compiled for the purpose of facilitating the application of various methods and tools for problem-solving. This dataset was obtained from the RottenTomatoes movie review website, which features over 300 pages. It includes six classes, as depicted in Figure or in Table below, and is licensed under the MIT license, allowing for both commercial and research use.
Label
Percentage, in %
Comedy
23
Drama
21.8
Horror
17.7
Mystery
14.4
Action
12.8
Kids
10.3
The general statistics of datasets are in Table below. The distribution of the number of characters, the number of words, the most common stop words and the most common words can be seen in the Figures below.
Train
Test
Articles
5495
788
Words
327357
47711
Vocabulary size
48721
48721
Metrics
The main metric by which students will be evaluated is Accuracy:
where N is the number of samples in the test dataset.
Baselines
In all implementations, we used the LabelEncoder from the scikit-learn library to translate a categorical target variable into a numeric data type.
Logistic Regression
To get a vector representation of the text, we trained TfidfVectorizer from the scikit-learn library with parameters:
We used the description of the films as a text feature into the model.
LSTM
For the validation set, we took 15% of all data and used the whole word as a token. Our dictionary consists of 30,000 of the most popular tokens in our corpus. And we get vector representations from a pre-trained Glove model: "glove-wiki-gigaword-100", where each vector has a dimension of 100.
Below are the configurations for the model and training, respectively:
We split the training set into train and val in the ratio of 85% and 15%, respectively, and for each text in both sets we received tokens by using a pre-trained tokenizer distilbert-base-uncased with parameters: truncation=True, do_lower_case=True. For the input sequence, we used a maximum length equal to 128 tokens and combined the examples into a batch of 64 elements each. The model had 6 classes and a dropout probability of 0.3. For training, we used the following configuration:
Our website uses cookies, including web analytics services. By using the website, you consent to the processing of personal data using cookies. You can find out more about the processing of personal data in the Privacy policy






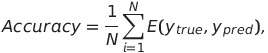
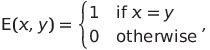 where N is the number of samples in the test dataset.
where N is the number of samples in the test dataset.

