Ended 13 months ago
01.06 — online доклады и активности Data Fest 2025
Встречаем лето с гипер-насыщенным днём докладов секций Data Fest 2025 🎉
Расписание online дня в spatial.chat
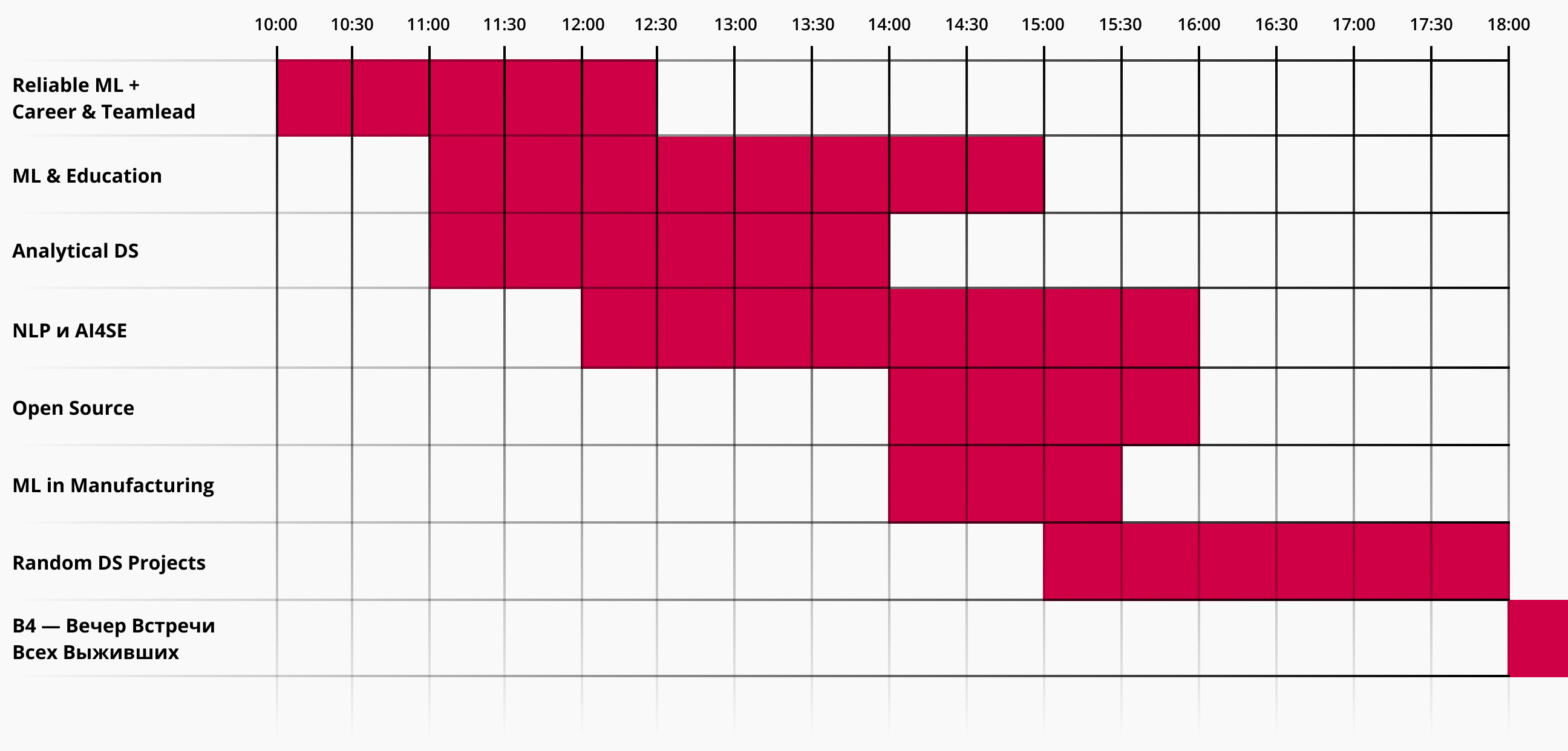
Секция Reliable ML + Career & Teamlead
10:00, Антон Воронов
LLM-tools в поиске работы
10:30, Олег Андриянов
Софт скиллы, которые реально влияют на твою зарплату
11:00, Соломонов Дмитрий
Эволюция тимлида: от стартапа до крупной компании
11:30, Андрей Тюняткин
Инкремент vs Эксперимент: Как снизить неопределённость при разработке ML-моделей
12:00, Михаил Катунькин
ML-Readability: Как Яндекс Браузер извлекает контент веб-страниц для пересказа
Секция ML & Education
11:00, Айрат Азбуханов
ИИ-тьюторы для обучения школьников
11:30, Татьяна Гайнцева
Образование в AI: ищем баланс между теорией и практикой
12:00, Полина Полунина
Почему руководителям по внедрению (или продактам) важно знать основы ML
12:30, Алексей Масютин
ИИ в образовании на примере кейсов НИУ ВШЭ
13:00, Александр Исаков
Как не утонуть в тонне материалов для развития
13:30, Данил Астафуров
От олимпиады до сеньора. Как превратить победу в карьеру
14:00, Ренат Исказиев
Как заинтересовать ИИ учащегося и педагога
14:30, Ренат Исказиев, Александр Гущин, Алексей Масютин, Полина Полунина, Андрей Кармацкий, Ульяна Артамошина
Пленарная сессия: что означает "хорошее" образование в AI ?
Секция Analytical DS
11:00, Дмитрий Забавин
UpLift RecSys: универсальный фреймворк разработки RecSys, нацеленной на рост доходности бизнеса
11:30, Ева Бронская
Как мы построили простую и эффективную аналитику для виртуальной примерочной
12:00, Анастасия Зинина
За всеми зайцами: как мы управляем разными типами контента в одной рекомендательной системе
12:30, Артемий Саранцев
Готовим плюшки правильно: как ML помогает проводить промоакции эффективно
13:00, Алина Бабенко
Сдаем с умом: запуск DS-продукта в краткосрочной аренде
13:30, Станислав Петров
Marketing Mix Modeling - как оно в 2025
Секции NLP и AI4SE
12:00, Мистергазе Александр [NLP]
Различение машинного и ручного переводов для языковой пары русский-венгерский
12:30, Корчемный Александр [NLP]
Графы и агенты в действии: как мы строим CoPilot для всех отделений Сбера.
13:00, Гетманов Андрей [AI4SE]
OSA: Как помочь учёным писать хороший код
13:30, Терещенко Андрей [AI4SE]
AI-инструменты для разработчиков: от обзора к эффективному внедрению
14:00, Москалев Дмитрий [AI4SE]
Data Catalog: моделирование и оптимизация связей между сущностями
14:30, Василиогло Эдуард [AI4SE]
DE Code Assistant: помогаем дата-инженерам писать трансформации
15:00, Дзюба Мария [AI4SE]
Генерация русскоязычных комментариев к коду
15:30, Ковалёв Алексей [Robotics]
Большие языковые и визуально-языковые модели в робототехнике
Секция Open Source
14:00, Александр Нозик
Экосистема открытого научного ПО KScience и возможности развития открытого ПО в вузах.
14:30, Дмитрий Кабанов
Как ученые-стратеги понимают open source
15:00, Антон Ширяев
VLMHyperBench — open-source фреймворк для оценки возможностей Vision language models (VLMs) распознавать документы на русском языке.
15:30, Мария Румянцева
CTCI - библиотека для анализа однородных промышленных данных.
Секция ML in Manufacturing
14:00, Сергей Зайцев
Повышение качества интерпретации аэрофотосъемки с применением диффузионных сетей
14:30, Павел Вавилов
Сегментация промышленных объектов на снимках Sentinel-2 с использованием YOLOv11
15:00, Алексей Каледин
Автоматическая идентификация фаз карбидокремниевой керамики на микроснимках с помощью U-Net
Секция Random DS Projects
15:00, Федор Жирков
Улучшение предсказания точки получения заказа
15:30, Анна Ариничева
Интерпретируемая классификация в NLP на примере выявления когнитивных искажений в тексте
16:00, Максим Алиев
ImbaML: эффективная несбалансированная классификация без экспертных знаний
17:30, Нафиса Валиева
Перевод датасета для оценки эмпатии на русском языке: подход, проблемы, результаты
В4 — Вечер Встречи Всех Выживших
18:00, все кто дожил до конца
Неформальный нетворкинг, вскрытие покровов про F-X
Our website uses cookies, including web analytics services. By using the website, you consent to the processing of personal data using cookies. You can find out more about the processing of personal data in the Privacy policy