The project devoted to the development of an approach for
definitions of bots and trolls in Russian-language comments on the YouTube service.
It was created as part of a project for the «Natural Language Processing course» by HUAWEI
nlphuaweiclusteringclassification
Deteсt trolls and bots in YouTube comments
Research project
For detection noise information (bot and troll messages) we need to make following:
Because we don't have labeled data we have to analyze data in order to be able to find method for noise message and usefully information separating. A small study was done to solve this problem. (See report and repository with project).
In the second part of project we need to develop machine learning model for troll and bots detection.
Team and contribution
At the moment, the project has only one main developer (email mixam.maxim@gmail.com), you are free to contact and ask any questions. We may discuss further development.
Related Work
A short list of related works and their descriptions can be found here.
Experiment design
Dataset
The data will be comments from YouTube channel "вДудь". On these videos, the blogger interviews famous actors, politicians, etc. The program for uploading comments to a file is in the repository.
Results
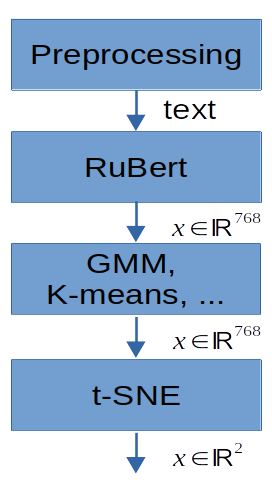
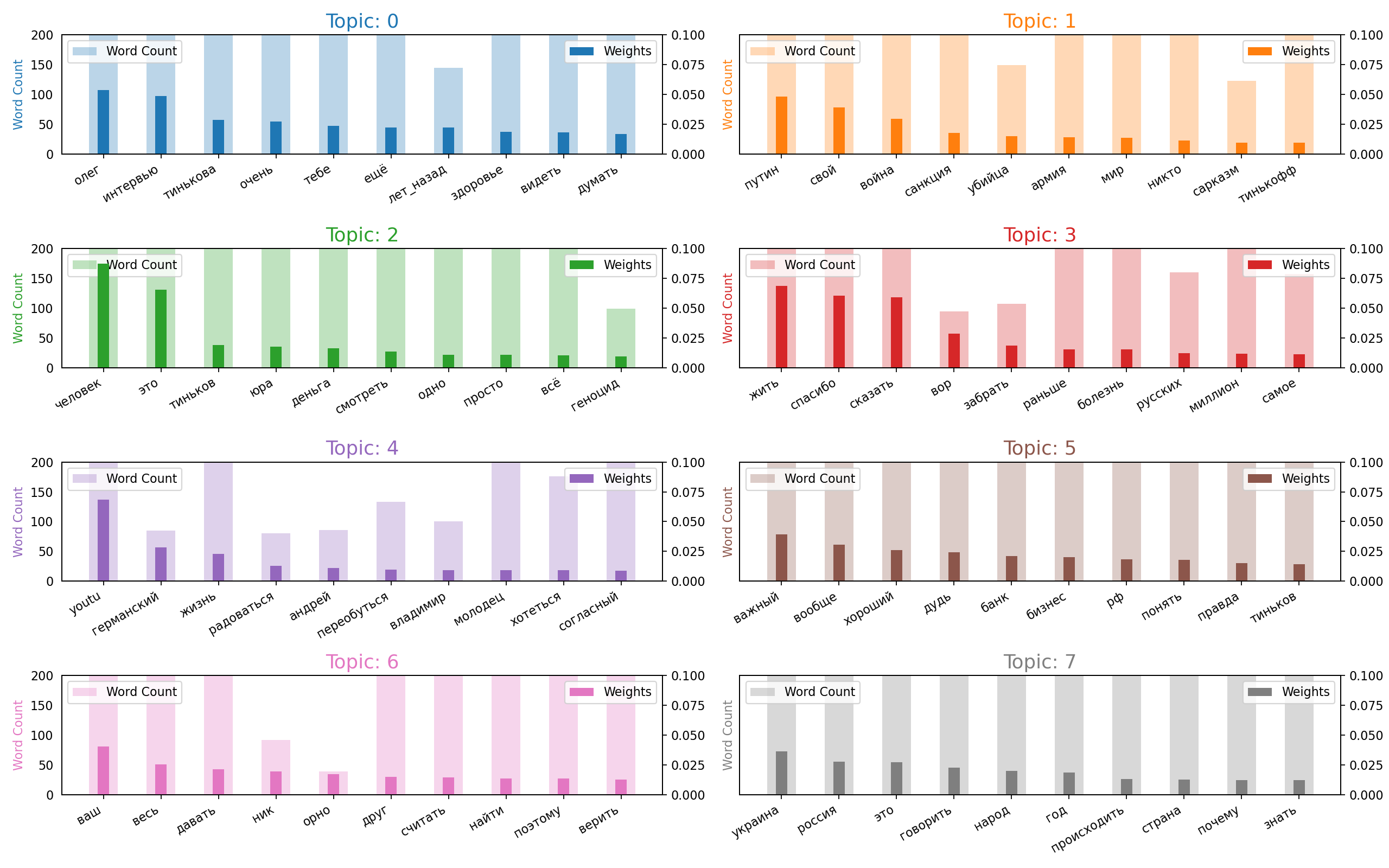
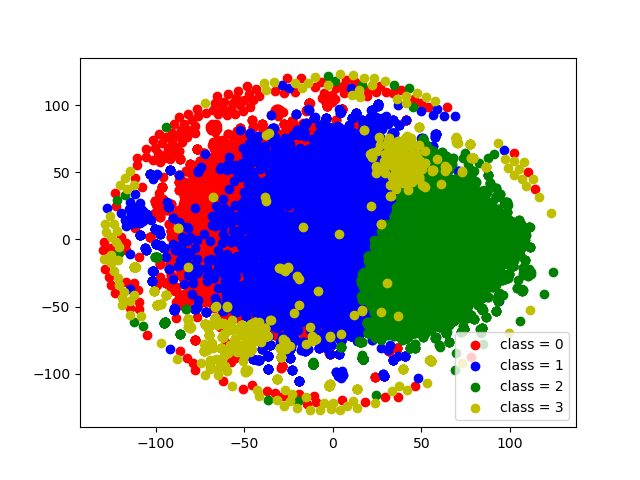
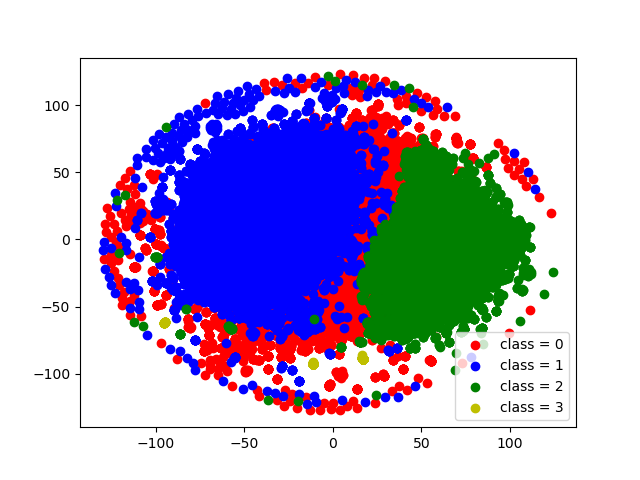
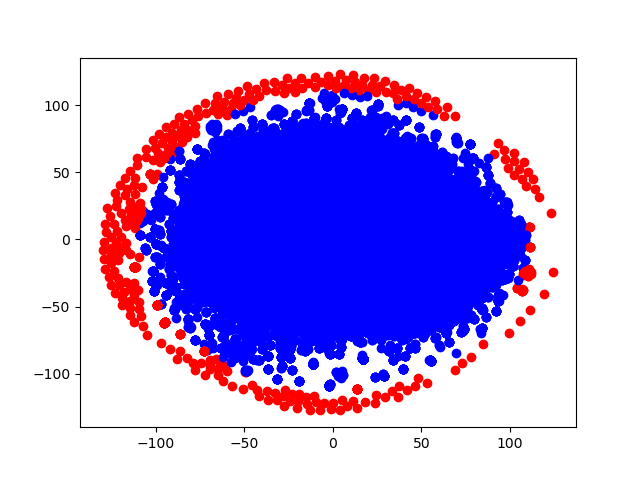
Three approaches were used to identify troll and bot comments (See pictures below too). The first is topic modeling with LDA. The second method of parsing messages is based on the use of embeddings obtained from RuBert. Further, for this vector representation, the GMM and K-means clustering methods were used. Based on the hand review of the data for the corresponding clusters, a conclusion was made about the class number to which the noise messages correspond. The third approach is {t-distributed} stochastic neighbor nesting (t-SNE) applied to RuBert embeddings. Noise comments were considered points lying on the periphery of a circle of a given radius.As a result, the analysis of texts that were marked as noise (with bots and trolls), we can conclude that thematic modeling showed the worst. There is a lot of information in his texts that does not look like the work of trolls and bots. Methods based on RuBert embeddings showed very good results. Approach based on the identification of noise points at the t-SNE boundary performance showed good results. This method does not require additional analysis of classes like all other methods. The only thing he selected is less than all the points (objects) for the noise class. This is due to the choice of a large circle radius.
Latent Dirichlet Allocation
On the following picture is demonstrated distribution of words in topics. We may guess that topic 6 has spam information.
t-SNE и GMM (Noise comments: class 3)
t-SNE и K-means (Noise comments: class 3)
t-SNE and selection of points on the periphery of a circle}
Our website uses cookies, including web analytics services. By using the website, you consent to the processing of personal data using cookies. You can find out more about the processing of personal data in the Privacy policy