Russian autism spectrum disorder and Asperger syndrome QA dataset
What is ASD QA?
Autism Spectrum Disorder QA, or ASD QA, is a project that supports the inclusion of people with special needs. First of all, it is a dataset for question-answering used for building an informational Russian language chatbot for the inclusion of people with autism spectrum disorder and Asperger syndrome in particular, based on the data from the informational website. The usage of the data is agreed.
The dataset is inspired by Stanford Question Answering Dataset (SQuAD), and was originally used to train a conceptual QA model for the chatbot for inclusive education. The dataset is available as an open source.
The dataset structure
The dataset includes sets of questions, answers and contexts with the relevant information for building retrieval-based QA systems. 5% of the questions are unanswerable and irrelevant, so the model can learn to ignore entertaining dialogue lines and give precise information only. The dataset contains 1 134 QA pairs, 179 174 symbols, 26 269 words. The number of reading passages is 96. The number of topic blocks is 3. The topics are the following (RU): (1) general information on ASD and Asperger's syndrome; (2) the interaction between neurotypical and atypical people; (3) sport and children with ASD — advice for parents. The work is in progress, and the amount of QA pairs will increase.
Fig. 1: A dataset sample
Versions
The dataset has several version. You can learn more on our FigShare page. You can also learn more from our NeurIPS 2021 paper.
Motivation and results
The inclusion of people with special needs becomes more widespread in Russia, although there is still lack of information and fake facts, which might cause misunderstandings and even conflicts between members of inclusive organizations (schools, colleges and universities, working organizations, etc.). Then, the idea of creating automated tools for the inclusion came up, but such tools need special closed domain datasets, and the work on such a dataset has soon been launched.
On the basis of the dataset, a closed domain model for question-answering in Russian was built with transfer learning techniques. Several BERT based models (multilingual BERT, ruBERT, XLM-R, RoBERTa), 117M and 774M GPT-2 were fine-tined on the custom dataset to build extractive (based on machine reading comprehension task) and generative (based on zero-shot learning) QA models respectively.
Crowdsource
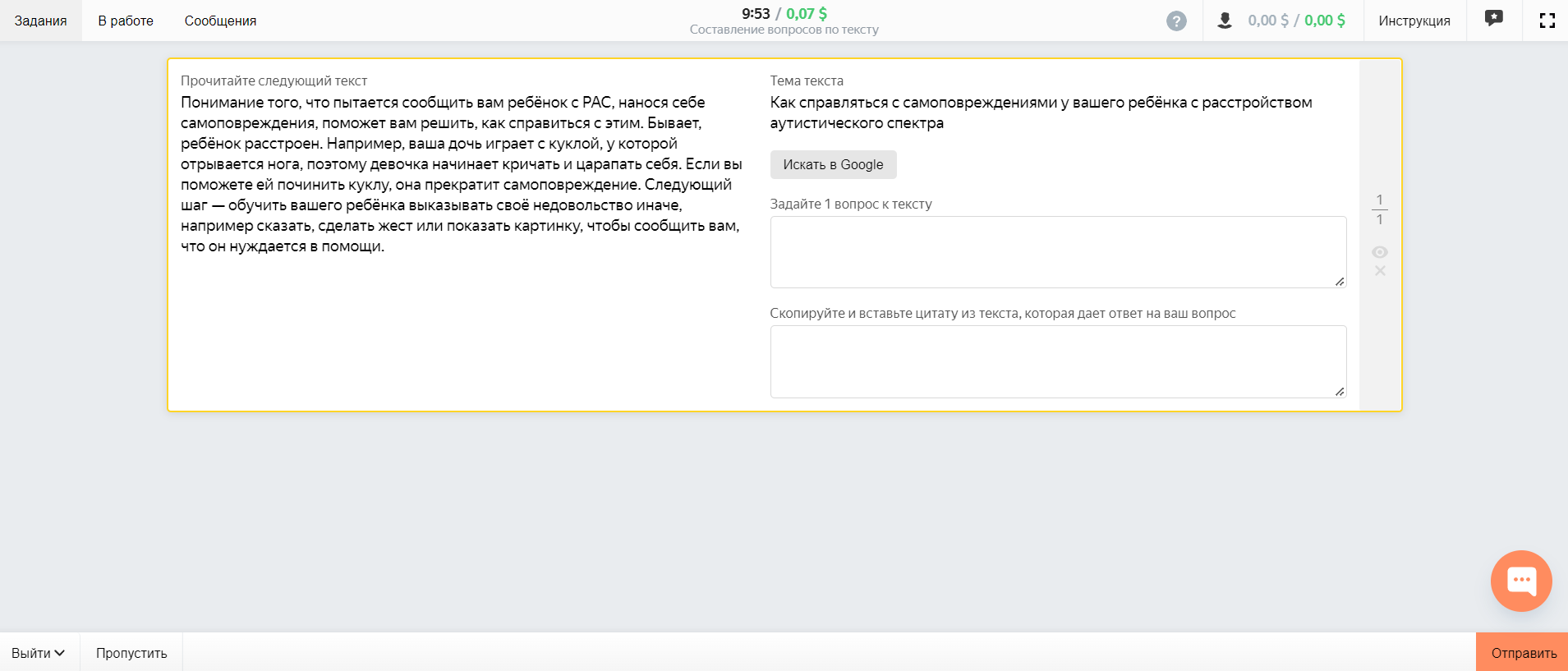
Fig. 2: A crowdsource task sample
In 2022, we have launched the crowdsource project to augment the dataset. The details of the crowdsource and the results will be announced later.
Results
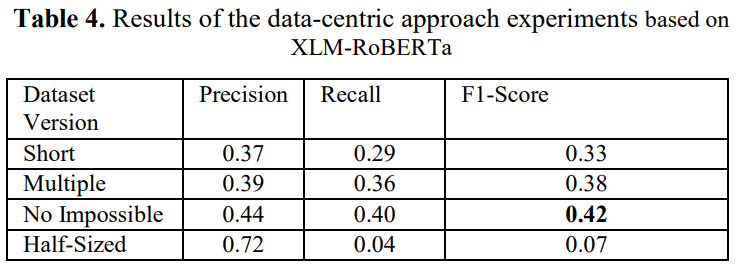
The following tables present some preliminary results obtained on the ASD QA dataset. We trained XLM-RoBERTa with the dataset and calculated Precision, Recall and F1-Score using different versions of the ASD QA.
Firsanova Victoria (2021). The Advantages of Human Evaluation of Sociomedical Question Answering Systems. International Journal of Open Information Technologies, 9 (12), 53-59.
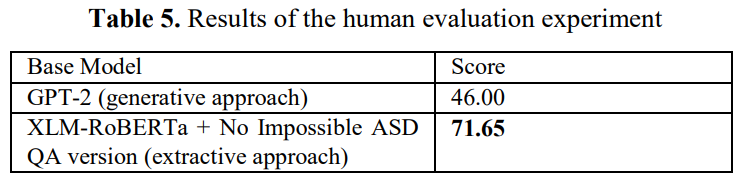
We have experimented with human evaluation. According to experts, extractive question answering (for example, BERT-based models) are preferable.
Firsanova Victoria (2021). The Advantages of Human Evaluation of Sociomedical Question Answering Systems. International Journal of Open Information Technologies, 9 (12), 53-59.
Our website uses cookies, including web analytics services. By using the website, you consent to the processing of personal data using cookies. You can find out more about the processing of personal data in the Privacy policy